Telegram 群组/频道目录 - Tghub

群组共2958页/每页10条
频道共23480页/每页10条
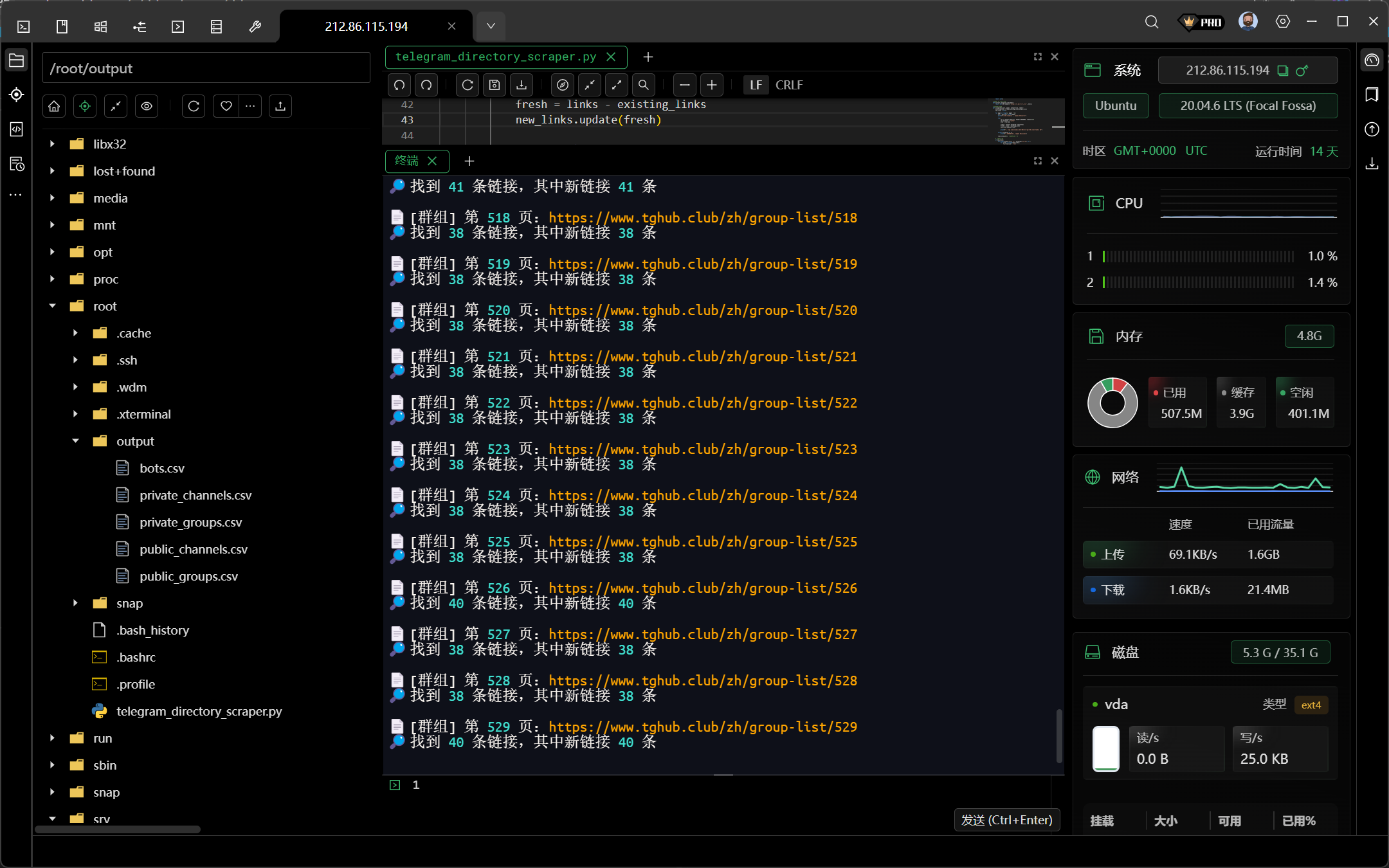
自动采集脚本代码,使用 python 编写
import os
import re
import time
import requests
# === 配置 ===
OUTPUT_DIR = "output"
os.makedirs(OUTPUT_DIR, exist_ok=True)
FILES = {
"群组": {
"公开": os.path.join(OUTPUT_DIR, "public_groups.txt"),
"私密": os.path.join(OUTPUT_DIR, "private_groups.txt")
},
"频道": {
"公开": os.path.join(OUTPUT_DIR, "public_channels.txt"),
"私密": os.path.join(OUTPUT_DIR, "private_channels.txt")
}
}
HEADERS = {
"User-Agent": "Mozilla/5.0"
}
# 加载历史记录
def load_existing_links(filepath):
if os.path.exists(filepath):
with open(filepath, "r", encoding="utf-8") as f:
return set(line.strip() for line in f if line.strip())
return set()
# 提取干净的 t.me 链接
def extract_telegram_links(html):
raw_links = re.findall(r'https://t\.me/[^\s"\'<>,;]+', html)
cleaned = set()
for link in raw_links:
# 去除尾部多余内容
link = re.split(r'[&<>"\'\s]', link)[0]
if re.match(r'^https://t\.me/[a-zA-Z0-9_+/]+$', link):
cleaned.add(link)
return cleaned
# 判断是否为私密链接
def is_private(link):
return '/+J' in link or '/+/' in link or '/+-' in link or '/+' in link
# 主采集逻辑
def scrape(base_url, pages, 类型):
public_file = FILES[类型]["公开"]
private_file = FILES[类型]["私密"]
existing_public = load_existing_links(public_file)
existing_private = load_existing_links(private_file)
new_public = set()
new_private = set()
for page in range(1, pages + 1):
url = base_url.format(page)
print(f"\n📄 [{类型}] 第 {page} 页:{url}")
try:
res = requests.get(url, headers=HEADERS, timeout=10)
res.encoding = "utf-8"
html = res.text
links = extract_telegram_links(html)
for link in links:
if is_private(link):
if link not in existing_private:
new_private.add(link)
else:
if link not in existing_public:
new_public.add(link)
print(f"🔎 找到 {len(links)} 个链接,新增公开 {len(new_public)}, 私密 {len(new_private)}")
except Exception as e:
print(f"❌ 抓取失败(第 {page} 页):{e}")
time.sleep(0.5) # 避免请求过快
# 写入新链接
if new_public:
with open(public_file, "a", encoding="utf-8") as f:
for link in sorted(new_public):
f.write(link + "\n")
if new_private:
with open(private_file, "a", encoding="utf-8") as f:
for link in sorted(new_private):
f.write(link + "\n")
print(f"\n✅ [{类型}] 新增公开 {len(new_public)} 条,新增私密 {len(new_private)} 条")
# === 主入口 ===
if __name__ == "__main__":
print("🚀 正在抓取 TGHUB Telegram 群组与频道...\n")
scrape("https://www.tghub.club/zh/group-list/{}", 10, "群组")
scrape("https://www.tghub.club/zh/channel-list/{}", 10, "频道")
print("\n🎉 所有任务完成!")
常驻运行命令:nohup python3 telegram_directory_scraper.py > output.log 2>&1 &